You know web scraping is a useful technique of data extraction from websites, especially if there is no any API or there is a ton of data that can’t be got in another way. The most simple and well-known way is to use CURL. But it is easy only in the aspect of using third-party components and widespread because of its universality. Our goal is to scrape data mostly simply for a programmer.
We are going to do this in 4 steps with Guzzle, Symfony DOM Crawler Component and Doctrine DBAL packages. As for an example of the site this one http://www.walmart.com will be taken.
We want to get all categories and goods from its catalogue and receive a CSV file with the goods at the end.
1. Install libraries
The easiest way to install all libraries with their requirements is to do this with Composer. We consider you have it installed.
1.1. Guzzle
The first thing we need for scraping is an HTTP Client. We choose Guzzle.
So let’s open command line and start with the command:
composer require guzzle/guzzle:~3.9
If install is successful you’ll see something like that:
C:\OpenServer\domains\walmart.loc>composer require guzzle/guzzle:~3.9 ./composer.json has been updated Loading composer repositories with package information Updating dependencies (including require-dev) - Installing symfony/event-dispatcher (v2.8.2) Loading from cache - Installing guzzle/guzzle (v.3.9.3) Loading from cache symfony/event-dispatcher suggests installing symfony/dependency-injection () symfony/event-dispatcher suggests installing symfony/http-kernel () guzzle/guzzle suggests installing guzzlehttp/guzzle (Guzzle 5 has moved to a new package name. The package you have installed, Guzzle 3, is deprecated.) Writing lock file Generating autoload files
As you can see one additional package was installed: symfony/event-dispatcher. It doesn’t need your special attention but it is a required dependency of Guzzle.
1.2. Symfony DOM Crawler Component
Also we need something that will help us to scrape necessary data quickly and easy. Here we’ll use Symfony DOM Crawler Component.
Write the next command into the command line:
composer require symfony/dom-crawlerThat’s how it will looks like if everything is OK:
C:\OpenServer\domains\walmart.loc>composer require symfony/css-selector Using version ^3.0 for symfony/dom-crawler ./composer.json has been updated Loading composer repositories with package information Updating dependencies (including require-dev) - Installing symfony/polyfill-mbstring (v1.1.0) Downloading: 100% - Installing symfony/dom-crawler (v.3..3) Downloading: 100% symfony/dom-crawler suggests installing symfony/css-selector () Writing lock file Generating autoload files
This package downloads additional package too, but also it suggests to install symfony/css-selector. It is very useful while scraping so we’ll accept this suggestion and write the following command:
composer require symfony/css-selectorYou can see an example of the successful installation process below:
C:\OpenServer\domains\walmart.loc>composer require symfony/dom-crawler Using version ^3.0 for symfony/dom-crawler ./composer.json has been updated Loading composer repositories with package information Updating dependencies (including require-dev) - Installing symfony/css-selector (v3.0.1) Downloading: 100% Writing lock file Generating autoload files
1.3. Doctrine
After getting data we’ll need to save it to the DB. That’s why some database abstraction layer will come in handy, for example, Doctrine.
The way of its installation is the same as at the previous step:
composer require doctrine/dbal:~2.5.4Here is a screenshot:
C:\OpenServer\domains\walmart.loc>composer require doctrine/dbal:~254 Using version ^3.0 for symfony/dom-crawler ./composer.json has been updated Loading composer repositories with package information Updating dependencies (including require-dev) - Installing doctrine/lexer (v1.0.1) Loading from cache - Installing doctrine/annotations (v1.2.7) Loading from cache - Installing doctrine/cache (v1.6.0) Downloading: 100% - Installing doctrine/inflector (v1.1.0) Downloading: 100% - Installing doctrine/common (v2.6.1) Downloading: 100% - Installing doctrine/dbal (v2.5.4) Downloading: 100% doctrine/dbal suggests installing symfony/console (For helpful console commands such as SQL execution and import of files.) Writing lock file Generating autoload files
At the end of this part let’s look to our project’s directory:
Here we see that all libraries are in the vendor directory and also composer.json and composer.lock files were created. So we can do the next step.
2. Load HTML code of the website page
We create file, for example, scraper.php in the root of project’s directory. Firstly, we need to include file vendor/autoload.php to make everything work:
<?php require __DIR__ . '/vendor/autoload.php'; ?>
2.1. Include Guzzle
Now we are ready to say that Guzzle client will be used. Also we need to think about some exceptions that may be thrown by this client.
use Guzzle\Http\Client; use Guzzle\Http\Exception\ClientErrorResponseException;
2.2. Create request
First of all let’s define some variables: URL of the site and URI of its page we want to scrape. Look at the http://www.walmart.com. In the menu there is a link to the page with all departments http://www.walmart.com/all-departments.
It is the best page for scraping categories, so we’ll use just it.
$url = 'http://www.walmart.com'; $uri = '/all-departments';
Also it is necessary to define User-Agent header.
If not, the following error will be produced:
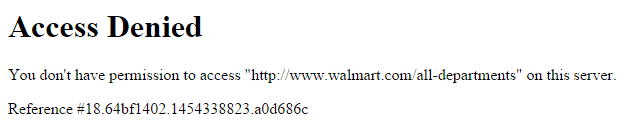
Let’s copy data from the browser. We will use Chrome default user-agent header.
$userAgent = 'Mozilla/5.0 (Windows NT 10.0)' . ' AppleWebKit/537.36 (KHTML, like Gecko)' . ' Chrome/48.0.2564.97' . ' Safari/537.36'; $headers = array('User-Agent' => $userAgent);
To make a request we need to create object of the HTTP Client and use its method get().
$client = new Client($url); $request = $client->get($uri, $headers);
2.3. Get response
When request is made we can get response from the http://www.wallmart.com. We will warp the request code block in try/catch to properly handle connection issues. Option true is required because we don’t want to echo page at the browser, we want to get it as a string.
try { $response = $request->send(); $body = $response->getBody(true); } catch (ClientErrorResponseException $e) { $responseBody = $e->getResponse() ->getBody(true); echo $responseBody; }
Now we have what to scrape so let’s move to the next part.
3. Scrape the page
3.1. Include Crawler
At the top of the script we’ll say we are going to use DOM Crawler Component and CSS Selector.
use Symfony\Component\DomCrawler\Crawler; use Symfony\Component\CssSelector;
3.2. Get HTML block with categories
Now let’s continue our try block. To scrape the received page’s body we should create an object of Crawler and put there the body variable.
It is time to see what part of page we have to extract to get the categories’ titles. We inspect it using Chrome Dev Tools and understand that we need the first div class='all-depts-links' (see screenshot below). It will be our filter.

Now we extract every child node of this div and push it to the array within the method each() and an anonymous function. After that we don’t need this Crawler object anymore so we’ll remove it.
$crawler = new Crawler($body); $filter = '.all-depts-links'; $catsHTML = $crawler ->filter($filter) ->each(function (Crawler $node) { return $node->html(); }); unset($crawler);
If we dump this array we’ll see 13 elements which are strings with the HTML inside.
Looking at it we get to know that we have three-level tree of categories: categories, their subcategories and sub-subcategories.

3.3 Get categories titles and subcategories HTML
Categories’ titles are located in the headings, so CSS selector for them is '.all-depts-links-heading > a'. Each subcategory locates in the separate li node, that’s why filter for them is 'ul'.
To get only titles from the categories’ headings is possibly using method text(). To get subcategories’ HTML code we’ll apply method html().
$cats = $subCatsHTML = array(); $catsFilter = '.all-depts-links-heading > a'; $subCatsFilter = 'ul'; foreach ($catsHTML as $index => $catHTML) { $crawler = new Crawler($catHTML); $cats[] = $crawler ->filter($catsFilter) ->text(); $subCatsHTML[$index] = array(); $subCatsHTML[$index] = $crawler ->filter($subCatsFilter) ->each(function (Crawler $node) { return $node->html(); }); unset($crawler); }
And now we have array with the categories title’s and the HTML code of subcategories.
3.4. Get subcategories’ and their sub-subcategories’ data
At this step we should receive an array with the whole data inside: categories titles’ and subcategories at the first level, subcategories’ data and their sub-subcategories at the second level, and sub-subcategories data at the third level.
From the screenshot above we know that CSS filter for the subcategories is 'li > a.all-depts-links-dept', and for the sub-subcategories it is 'li > a.all-depts-links-category'.
Let’s think about data that we need to get from subcategories. Of course, the first field is a title. But also as we are going to get products from this subcategory, we need to know how to get to its page. So the second field will be a link, namely an URI for the subcategory’s page. The same we need for sub-subcategories.
The code for this section will look like this:
$subSubCats = array(); $subCatsFilter = 'li > a.all-depts-links-dept'; $subSubCatsFilter = 'li > a.all-depts-links-category'; foreach ($subCatsHTML as $catIndex => $subCatHTML) { $subSubCats[$catIndex]['cat'] = $cats[$catIndex]; foreach ($subCatHTML as $subCatIndex => $subSubCatHTML) { $crawler = new Crawler($subSubCatHTML); $node = $crawler->filter($subCatsFilter); $tempSubCat = array( 'href' => $node->attr('href'), 'title' => $node->text() ); $tempSubSubCats = $crawler ->filter($subSubCatsFilter) ->each(function (Crawler $node) { return array( 'href' => $node->attr('href'), 'title' => $node->text() ); }); unset($crawler); $subSubCats[$catIndex]['subCats'][$subCatIndex] = array( 'subCat' => $tempSubCat, 'subSubCats' => $tempSubSubCats ); } }
3.5. Get goods
In the Walmart catalogue some of the subcategories don’t have sub-subcategories. That’s why our task is to get goods:
- from the subcategories without sub-subcategories;
- from the sub-subcategories.
All goods are located inside the list with classed 'tile-list tile-list-grid'. Every item has its own ul
and all item’s data is inside child node of li – div.
Being based on these conclusions we can form a goods filter: 'ul.tile-list.tile-list-grid > li > div'.
One more thing before we dive into the code.
While writing and testing this script we noticed that Guzzle was redirected from some links to others. But HTTP client couldn’t do this automatically, so it threw an exception with a such message: “Was unable to parse malformed url: http://url/to/what/it/was/redirected”. But we caught this exception, got the URL from it and went ahead with the new URL.
$errorMessage = 'Was unable to parse malformed url: '; $errorLength = strlen($errorMessage); $goodsFilter = 'ul.tile-list.tile-list-grid > li > div'; foreach ($subSubCats as $catIndex => $cats) { if (!empty($cats['subCats'])) { foreach ($cats['subCats'] as $subCatIndex => $subCat) { if (empty($subCat['subSubCats'])) { $uri = $subCat['subCat']['href']; $goodsHTML = ''; $continue = true; while (empty($goodsHTML) && $continue) { if (strpos($uri, 'http') === false) { $uri = $url . $uri; } $request = $client->get($uri, $headers, $options); try { $response = $request->send(); $goodsHTML = $response->getBody(true); $crawler = new Crawler($goodsHTML); $subSubCats[$catIndex]['subCats'] [$subCatIndex]['goods'] = array(); $subSubCats[$catIndex]['subCats'] [$subCatIndex]['goods'] = $crawler ->filter($goodsFilter) ->each(function(Crawler $node) { $html = $node->html(); return getGoodsData( $html, $node ); }); unset($crawler); } catch(Exception $e) { $message = $e->getMessage(); if (strpos($message, $errorMessage) === false) { $continue = false; } else { $uri = substr($message, $errorLength); } } } } else { foreach ( $subCat['subSubCats'] as $subSubCatIndex => $subSubCat ) { $uri = $subSubCat['href']; $goodsHTML = ''; $continue = true; while (empty($goodsHTML) && $continue) { if (strpos($uri, 'http') === false) { $uri = $url . $uri; } $request = $client->get($uri, $headers, $options); try { $response = $request->send(); $goodsHTML = $response->getBody(true); $crawler = new Crawler($goodsHTML); $subSubCats[$catIndex]['subCats'] [$subCatIndex]['subSubCats'] [$subSubCatIndex]['goods'] = array(); $subSubCats[$catIndex]['subCats'] [$subCatIndex]['subSubCats'] [$subSubCatIndex]['goods'] = $crawler ->filter($goodsFilter) ->each(function(Crawler $node) { $html = $node->html(); return getGoodsData( $html, $node ); }); unset($crawler); } catch(Exception $e) { $message = $e->getMessage(); if (strpos($message, $errorMessage) === false) { $continue = false; } else { $uri = substr($message, $errorLength); } } } } } } } }
In the code above we used earlier undefined function getGoodsData($html, $node). Before we write it we need to know what data we want to get from goods. Looking at some sub-subcategory’s page (see screenshot below) we see that goods have such main attributes. But sometimes some fields may be absent: at the screenshots below there is no price or there are no rating and reviews.

We should prevent problems associated with these cases so it is obvious to set default values for these variables. Also it is necessary to check if these spans are present in the received HTML code.
Also let’s prepare filters for the data:
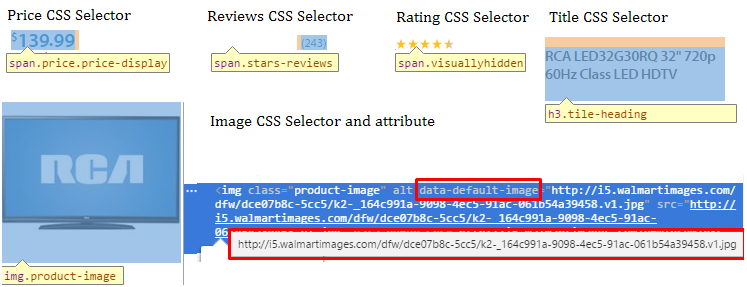
Now we can write the function.
function getGoodsData($html, Crawler $node) { $price = $rating = .0; $reviews = 0; $image = $title = ''; $priceSpan = '<span class="price price-display">'; $priceFilter = 'span.price.price-display'; $ratingSpan = '<span class="visuallyhidden">'; $ratingFilter = 'span.visuallyhidden'; $reviewsSpan = '<span class="stars-reviews">'; $reviewsFilter = 'span.stars-reviews'; $imageFilter = 'a > img'; $titleFilter = 'h3.tile-heading'; if (!(strpos($html, $priceSpan) === false)) { $price = $node ->filter($priceFilter) ->text(); $price = trim($price); $price = substr($price, 1); $price = str_replace(',', '', $price); $price = (float) $price; } if (!(strpos($html, $ratingSpan) === false)) { $rating = $node ->filter($ratingFilter) ->text(); $rating = (float) $rating; } if (!(strpos($html, $reviewsSpan) === false)) { $reviews = $node ->filter($reviewsFilter) ->text(); $reviews = trim ($reviews); $reviews = str_replace('(', '', $reviews); $reviews = str_replace(')', '', $reviews); $reviews = (int) $reviews; } $image = $node ->filter($imageFilter) ->attr('data-default-image'); $title = $node ->filter($titleFilter) ->text(); $title = trim($title); return compact('image', 'price', 'title', 'rating', 'reviews'); }
4. Push data into DB
4.0. Create DB
Let’s create a database called 'walmart'. We can do this easy within PHPMyAdmin or MySQL console. Here is an SQL script:
DROP DATABASE IF EXISTS `walmart`; CREATE DATABASE `walmart`;
4.1. Include Doctrine
To include Doctrine into our script we’ll do three steps:
require __DIR__ . '/vendor/doctrine/common/lib/Doctrine/Common/ClassLoader.php';
use Doctrine\Common\ClassLoader;
$classLoader = new ClassLoader( 'Doctrine', __DIR__ . '/vendor/doctrine/common' ); $classLoader->register();
4.2. Configure and set connection
The next step is to create an object of Doctrine class.
$config = new \Doctrine\DBAL\Configuration(); $connectionParams = array( 'dbname' => 'walmart', 'user' => 'root', 'password' => '', 'host' => 'localhost', 'driver' => 'pdo_mysql', ); $conn = \Doctrine\DBAL\DriverManager::getConnection( $connectionParams, $config );
4.3. Create tables
Firstly let’s write an SQL code into the SQL file.
DROP TABLE IF EXISTS `categories`; CREATE TABLE IF NOT EXISTS `categories` ( `category_id` tinyint(2) UNSIGNED NOT NULL AUTO_INCREMENT, `category_title` VARCHAR(30) NOT NULL, PRIMARY KEY (`category_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 AUTO_INCREMENT=1; DROP TABLE IF EXISTS `goods`; CREATE TABLE IF NOT EXISTS `goods` ( `goods_id` INT(4) UNSIGNED NOT NULL AUTO_INCREMENT, `subcategory_id` INT(3) UNSIGNED DEFAULT NULL, `subsubcategory_id` INT(3) UNSIGNED DEFAULT NULL, `goods_title` VARCHAR(210) NOT NULL, `goods_image` VARCHAR(125) NOT NULL, `goods_price` DECIMAL(5,2) NOT NULL, `goods_reviews` INT(5) NOT NULL, `goods_rating` DECIMAL(1,1) NOT NULL, PRIMARY KEY (`goods_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 AUTO_INCREMENT=1; DROP TABLE IF EXISTS `subcategories`; CREATE TABLE IF NOT EXISTS `subcategories` ( `subcategory_id` INT(3) UNSIGNED NOT NULL AUTO_INCREMENT, `category_id` tinyint(2) UNSIGNED NOT NULL, `subcategory_title` VARCHAR(35) NOT NULL, `subcategory_href` VARCHAR(160) NOT NULL, PRIMARY KEY (`subcategory_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 AUTO_INCREMENT=1; DROP TABLE IF EXISTS `subsubcategories`; CREATE TABLE IF NOT EXISTS `subsubcategories` ( `subsubcategory_id` INT(3) UNSIGNED NOT NULL AUTO_INCREMENT, `subcategory_id` INT(3) UNSIGNED NOT NULL, `subsubcategory_title` VARCHAR(35) NOT NULL, `subsubcategory_href` text NOT NULL, PRIMARY KEY (`subsubcategory_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 AUTO_INCREMENT=1;
Now we execute it in the command line:
C:\OpenServer\modules\database\MySQL-5.5\bin>mysql -h localhost -u root -p -D walmart < C:\OpenServer\domains\walmart.loc\walmart.sql Enter password:
Let’s verify if our tables were created.
4.4. Insert goods into DB
At last we get to the final part.
Here we are going to walk through the array and insert every category, subcategory, sub-subcategory and goods item. Notice that we need to create variables for subcategory and sub-subcategory indices, and increment them at every iteration, because their indices in the array get to zero at every level.
$sql = array(); $sql['cat'] = 'INSERT INTO `categories` ' . '(`category_id`, `category_title`)' . 'VALUES (?, ?);'; $sql['subCat'] = 'INSERT INTO `subcategories` ' . '(`subcategory_id`, `category_id`, ' . '`subcategory_title`, `subcategory_href`) ' . 'VALUES (?, ?, ?, ?)'; $sql['subSubCat'] = 'INSERT INTO `subsubcategories` ' . '(`subsubcategory_id`, `subcategory_id`, ' . '`subsubcategory_title`, `subsubcategory_href`) ' . 'VALUES (?, ?, ?, ?)'; $sql['goods'] = 'INSERT INTO `goods` ' . '(`subcategory_id`, `subsubcategory_id`, ' . '`goods_image`, `goods_price`, `goods_title`, ' . '`goods_rating`, `goods_reviews`) ' . 'VALUES (?, ?, ?, ?, ?, ?, ?)'; $subCatID = $subSubCatID = 0; foreach ($subSubCats as $catIndex => $cat) { $conn->executeQuery($sql['cat'], array($catIndex + 1, $cat['cat'])); foreach ($cat['subCats'] as $subCatIndex => $subCat) { $subCatID++; $conn->executeQuery($sql['subCat'], array($subCatID, $catIndex + 1, $subCat['subCat']['title'], $subCat['subCat']['href'] )); if (!empty($subCat['subSubCats'])) { foreach ( $subCat['subSubCats'] as $subSubCatIndex => $subSubCat ) { $subSubCatID++; $conn->executeQuery($sql['subSubCat'], array($subSubCatID, $subCatID, $subSubCat['title'], $subSubCat['href'] )); if (!empty($subSubCat['goods'])) { foreach ($subSubCat['goods'] as $item) { $conn->executeQuery($sql['goods'], array(null, $subSubCatID, $item['image'], $item['price'], $item['title'], $item['rating'], $item['reviews'] )); } } } } if (!empty($subCat['goods'])) { foreach ($subCat['goods'] as $item) { $conn->executeQuery($sql['goods'], array($subCatID, null, $item['image'], $item['price'], $item['title'], $item['rating'], $item['reviews'] )); } } } }
Now we have all goods from the first pages of every category located in our database. Let’s export table ‘goods’ to CSV file. Here we have 20 rows from this file:
goods_id,"subcategory_id","subsubcategory_id","goods_title","goods_image","goods_price","goods_reviews","goods_rating" 1,NULL,"1","RCA LED40HG45RQ 40"" 1080p 60Hz Class LED HDTV","http://i5.walmartimages.com/dfw/dce07b8c-f340/k2-_f1748cc7-f639-4859-8558-7559959b32bb.v1.jpg","230","227","4" 2,NULL,"1","Sceptre E405BD-F 40"" 1080p 60Hz LED HDTV with Built-in DVD Player","http://i5.walmartimages.com/dfw/dce07b8c-89de/k2-_d45babb1-d7ba-461d-b2e4-0ae9dac7243a.v2.jpg","250","37","5" 3,NULL,"1","SCEPTRE X405BV-F 40"" LED Class 1080P HDTV with ultra slim metal brush bezel, 60Hz","http://i5.walmartimages.com/dfw/dce07b8c-3578/k2-_8725da99-da45-4a8a-b94a-9863ea26fb40.v1.jpg","240","5267","5" 4,NULL,"1","Samsung 40"" 1080p 60Hz LED HDTV, UN40H5003AFXZA","http://i5.walmartimages.com/dfw/dce07b8c-3fc2/k2-_99695518-7c25-44c8-b335-d6a44029510e.v1.jpg","0","492","0" 5,NULL,"1","Samsung 40"" 1080p 60Hz LED Smart HDTV, UN40H5203AFXZA","http://i5.walmartimages.com/dfw/dce07b8c-2b20/k2-_13957163-be6a-4793-889c-a802b801f059.v1.jpg","328","642","5" ... 41,NULL,"2","LG BP155 Wired Blu-ray Player","http://i5.walmartimages.com/dfw/dce07b8c-c530/k2-_e70f57bb-dcf0-41ef-8cc1-cccdce5d194d.v1.jpg","45","34","4" 42,NULL,"2","Sony DVD Player, DVPSR210P","http://i5.walmartimages.com/dfw/dce07b8c-de92/k2-_2a1c6a2e-5413-41ae-af94-56daf9a86867.v3.jpg","38","954","4" 43,NULL,"2","Sony BDP-S3500 2D Blu-ray Player with WiFi","http://i5.walmartimages.com/dfw/dce07b8c-17a9/k2-_f81e14de-aebc-40e6-bcf1-99826f1154b5.v1.jpg","80","334","5" 44,NULL,"2","Sony DVP-SR510H HDMI DVD Player","http://i5.walmartimages.com/dfw/dce07b8c-a8af/k2-_d4b2e9a7-4c42-4f38-8dd8-8918534f4ce6.v1.jpg","0","532","0" 45,NULL,"2","LG DP132 DVD Player","http://i5.walmartimages.com/dfw/dce07b8c-1a82/k2-_ccd9e7cc-7144-47a8-ba20-a03a44cc607e.v1.jpg","28","85","4" ... 885,"19",NULL,"16 oz Jurassic World Plastic Cup","http://i5.walmartimages.com/dfw/dce07b8c-6ef4/k2-_3eb98ef0-55c5-4afb-b1db-779b4b1e55a9.v1.jpg","2","3","5" 886,"19",NULL,"LEGO: Jurassic World (PSV)","http://i5.walmartimages.com/dfw/dce07b8c-a756/k2-_00d0c9a5-50d5-426b-b441-92cc8f35d916.v1.jpg","20","1","5" 887,"19",NULL,"Dinosaur Field Guide","http://i5.walmartimages.com/dfw/dce07b8c-2aac/k2-_53a1e3a9-7beb-44de-bb11-4cabaf5b387c.v3.jpg","6","1","5" 888,"19",NULL,"Jurassic World Chomping Indominus Rex Figure","http://i5.walmartimages.com/dfw/dce07b8c-55f9/k2-_4b7d8ea1-47d0-41c1-aa3f-9f2c2ffb8146.v1.jpg","45","12","4" 889,"19",NULL,"Jurassic Park: The Ultimate Trilogy","http://i5.walmartimages.com/dfw/dce07b8c-c62c/k2-_16303f8e-7a2c-470c-a03e-2df5e849ab29.v1.jpg","30","33","5" ... 925,"21",NULL,"Minions (Blu-ray + DVD + Digital HD)","http://i5.walmartimages.com/dfw/dce07b8c-d537/k2-_989c072c-8901-4b27-aaca-d81d496697ac.v5.jpg","15","160","5" 926,"21",NULL,"Minions (Blu-ray + DVD + Digital HD + Minion Water Bottle) (Walmart Exclusive)","http://i5.walmartimages.com/dfw/dce07b8c-4439/k2-_4fe1c5eb-6c37-44ef-afd7-b9c288acdaa7.v2.jpg","25","160","5" 927,"21",NULL,"Minions","http://i5.walmartimages.com/dfw/dce07b8c-a453/k2-_1414b630-61ed-4510-b91d-872e268384c0.v4.jpg","13","160","5" 928,"21",NULL,"16 oz Despicable Me Plastic Cup","http://i5.walmartimages.com/dfw/dce07b8c-acba/k2-_cb2cfc49-55a4-48c5-8b6a-b2b1257d530f.v1.jpg","2","12","5" 929,"21",NULL,"Universal's Minions Fabric Shower Curtain","http://i5.walmartimages.com/dfw/dce07b8c-6322/k2-_9ac7a4b5-ac56-45d3-9cfa-99001d589e69.v1.jpg","20","1","5" 930,"21",NULL,"Universal's Minions Bath Rug","http://i5.walmartimages.com/dfw/dce07b8c-cbf7/k2-_207e62b7-1908-46c9-a5b1-28876aaa8876.v1.jpg","15","0","0"
2. Load HTML code of the website page
We create file, for example, scraper.php in the root of project’s directory. Firstly, we need to include file vendor/autoload.php to make everything work:
——————–
I am using symfony 4…. This does not seem right where do you put this file exactly? Because it seems to me it should go in the src folder?
Hi Dustin,
thanks for commenting! This tutorial has been created with the thought, that you don’t use any MVC frameworks for the task. I.e. only guzzle+doctrine/dbal+symfony dom crawler (which is just a component of symfony framework). You definitely can use sf4 to create a similar scraper, but in this case I’d do it as a console symfony command (read more here: https://symfony.com/doc/current/console.html ). Note that the framework does all the autoloading tasks for you, so in case you prefer to go with sf console command, you just need to specify the namespaces used, no need to do any require/include’s.
Hope you can create such a command for your symfony project!
Is there a git repo for the entire codebase?
Is there a git repo where I can download this project? Thank you.
I was hoping for a git hub repo as well.
Hi Rick, thanks for your interest! We just finished an updated article on this topic, completely rewrote it: https://lamp-dev.com/scraping-products-from-walmart-with-php-phantomjs-symfony-crawler-and-doctrine-ver-2/1729 and here is the github repo with the code from the new article: https://github.com/lampdev/scraper